
Loading Data to BigQuery using Google Workflow
Overview
Sometimes you have data that is not in BigQuery, but which you would like to send to BigQuery. It’s a big and scary world out there when it comes to syncing data between different storage services and data warehouses. But it doesn’t have to be scary!
In this post we will look at how CTA uses Google Workflows to transfer data into BigQuery from S3 and Google Drive.
Google Workflows
Google Workflows is one of the (many) services offered in Google Cloud Platform. It enables the user (this could be you!) to easily orchestrate processes using a simple YAML file.
This is particularly useful when you are performing tasks that use the Google API and Google Cloud Services. Rather than needing to write and deploy custom code to handle different APIs, Google Workflows makes it simple to configure tasks and set up dependencies between them.
AWS S3 to BigQuery
There are a ton of different ways data can be moved from S3 to BigQuery. Here we demonstrate how CTA achieves this using only Google Cloud Services. Specifically, we take three basic steps:
Storage Transfer Service (STS) synchronizes the S3 bucket with a Cloud Storage (GCS) bucket
The BigQuery API loads data from GCS into BQ, and
Google Workflows orchestrates the entire process.
Prerequisites
In order for this to work the following things need to be set up:
Configure access to AWS S3 - here are some GCP provided docs for setting up the needed access to transfer data from S3. We use Access Credentials to set this up.
Create a Service Account for Workflows to run with and grant necessary permissions.
Make sure the BigQuery API is enabled.
Create a BigQuery Dataset where we will deliver the data.
Pro Tip: If you are an organization working with Community Tech Alliance, you already have all of this set up for you! Learn more here.
Create an STS transfer
Google has already written some good documentation on setting up a transfer that you can follow. But I’ll still add some details on how we set up a transfer.
Head over to the STS page on the Google Cloud Console and click on Create Transfer Job. This will take you to the Create page, set the source to S3 and destination to GCS.
!https://miro.medium.com/v2/resize:fit:1400/1*7HHqkHB5t7cdx38lujqXnQ.png
{kind=link}
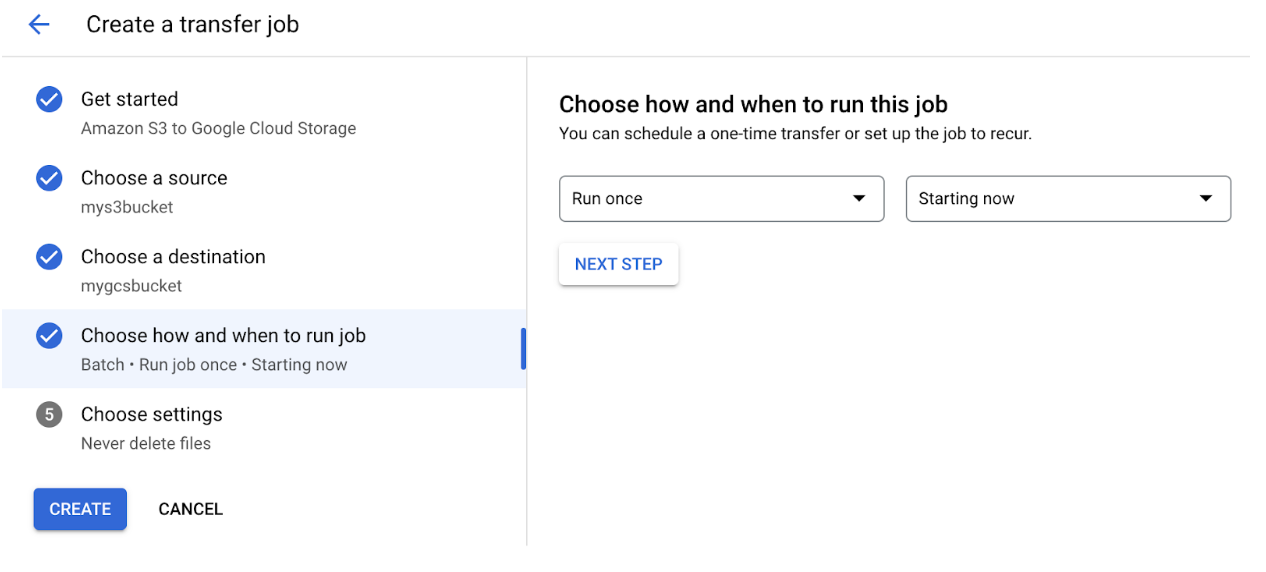
Fill in your source information and add your S3 credentials for Step 2. Then choose your destination GCS bucket on Step 3. For the initial set up, we chose to Run the job once starting now.
!https://miro.medium.com/v2/resize:fit:1400/1*WTUg2xL6muo6E5uBZpSs6Q.png
{kind=link}
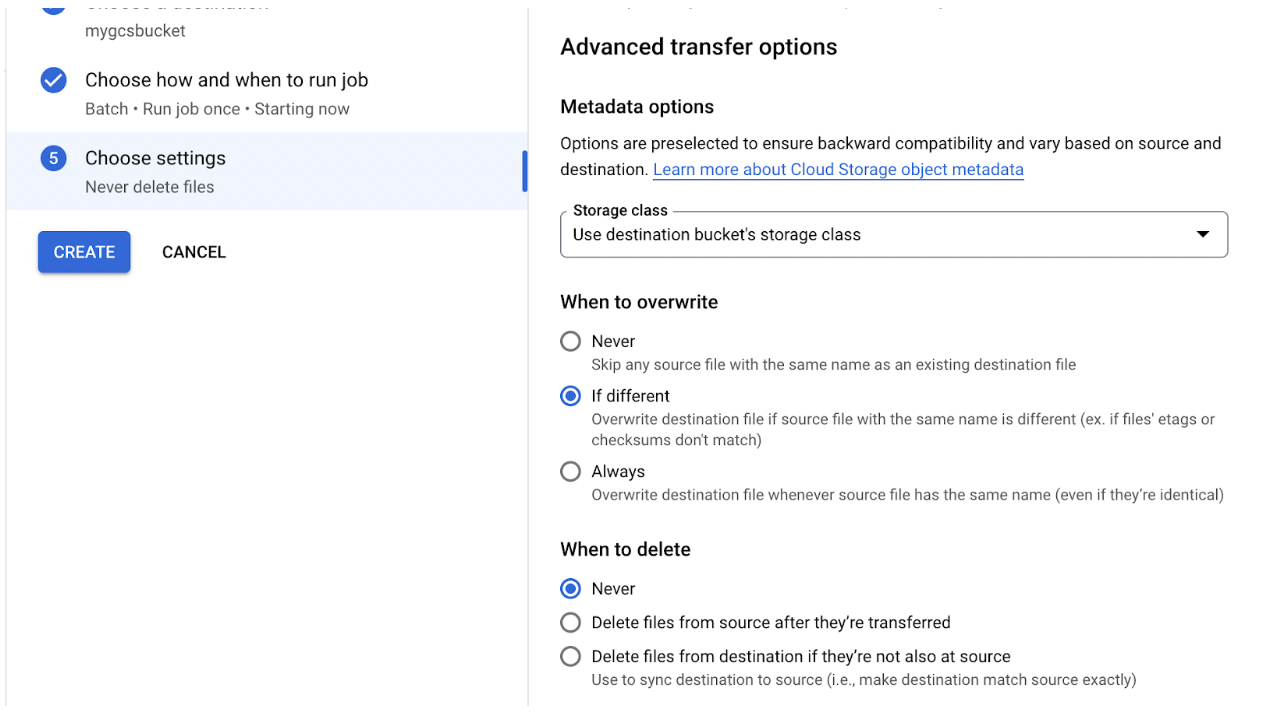
Finally, we configure some additional transfer settings:
!https://miro.medium.com/v2/resize:fit:1400/1*YUuI_Vu-lMfUtyK75JdRvQ.png
{kind=link}
Create the Workflow
Google Workflows are defined by a YAML file. To get started, open up your favorite text editor and create a YAML file. First, we will assign some variables to be passed in when the workflow is triggered. These variables allow us to configure:
The destination BigQuery table we want to load data into (identified by dest_project_id, dest_dataset_id, and dest_table_id)
The GCS source URI to load, and
The name we want to give to the STS transfer job.
# Arguments # - dest_project_id (String) # Project ID of Destination Table # - dest_dataset_id (String) # Dataset ID of Destination Table # - dest_table_id (String) # Table Name of Destination Table # - source_uri (String) # Full Cloud Storage Path of Source File(s) (ex. gs://path/to/file.txt.gz or ["gs://path/to/file.txt.gz", etc..]) # - transfer_job_name (String) # Full Name of transfer job that syncs S3 to GCS bucket (ex. transferJobs/123456789) main: params: [args] steps: - init: assign: - dest_project_id: ${args.dest_project_id} - dest_dataset_id: ${args.dest_dataset_id} - dest_table_id: ${args.dest_table_id} - source_uri: ${args.source_uri} - transfer_job_name: ${args.transfer_job_name}
Our first step is to run the STS transfer job, which will load any new data that has not yet been synced from S3. Google Workflows provides a connector for the Storage Transfer Service that we can use to start a job run.
- run_s3_to_gcs_transfer: call: googleapis.storagetransfer.v1.transferJobs.run args: jobName: ${transfer_job_name} body: projectId: ${dest_project_id} result: transfer_result
Next, we use the BigQuery Connector to create a Load job to load data from a GCS bucket to BigQuery.
- load_data_into_bq_table: call: googleapis.bigquery.v2.jobs.insert args: projectId: ${dest_project_id} body: configuration: load: createDisposition: CREATE_IF_NEEDED writeDisposition: WRITE_TRUNCATE sourceUris: ${source_uri} destinationTable: projectId: ${dest_project_id} datasetId: ${dest_dataset_id} tableId: ${dest_table_id} skipLeadingRows: 1 result: load_result
And you’re done!
For our use case, we wanted to take an additional step to set up automated alerts when any step in the workflow fails. To enable this, we added some logs to our workflow that we can use to trigger those alerts. This is set up by wrapping each workflow call with a try/catch block. Within the catch you can add any number of steps. Here’s an example that will create a detailed log of the failure.
- run_s3_to_gcs_transfer: try: call: googleapis.storagetransfer.v1.transferJobs.run args: jobName: ${transfer_job_name} body: projectId: ${dest_project_id} result: transfer_result except: as: error steps: - log_transfer_job_error: call: sys.log args: severity: "ERROR" json: workflow_execution_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")} source_uri: ${source_uri} transfer_job_name: ${transfer_job_name} target_destination: projectId: ${dest_project_id} datasetId: ${dest_dataset_id} tableId: ${dest_table_id} sync_status: "FAILED" error_message: ${error} - raise_error_to_halt_execution: raise: error
Make sure that you are adding a step in your except block to re-raise the error and halt execution of the workflow.
steps: - log_transfer_job_error: ... - raise_error_to_halt_execution: raise: error
That’s it! You now have a workflow that can be used to load data from S3 into BigQuery, and with just a little extra effort, your workflow will emit logs that you can use to set up automated alerting using Google Monitoring. You can schedule this workflow to run on any schedule you would like or run it ad hoc, depending on your use case. And here is a link to the full workflow code.
Google Drive to BigQuery
For the next example, we will create a Workflow that iterates through a Google Drive Folder and loads CSV files into their own BigQuery tables. Note: this is distinct from BigQuery’s native functionality to query Google Spreadsheets as external tables. The process described below allows us to query multiple files stored in Drive (similar to how one might store data in Google Cloud Storage).
Prerequisites
In order for this to work the following things need to be set up:
Create a Service Account for Workflows to run with and grant necessary permissions
Make sure the Drive API is enabled
Make sure the BigQuery API is enabled
Create the Workflow
First, let’s assign the variables that are going to be passed in when the workflow is run. Here, we’re just taking in the ID of the base Drive folder that contains the data we want to load and the BigQuery Destination project and dataset IDs.
# This workflow loads data from Google Drive to BQ. # # Arguments: # - base_drive_folder_id (String) # The root Google Drive Folder ID # - dest_project_id (String) # Project ID of where data should be loaded # - source_dataset_id (String) # Dataset where data should be loaded main: params: [args] steps: - init: assign: - base_drive_folder_id: ${args.base_drive_folder_id} - dest_project_id: ${args.dest_project_id} - dest_dataset_id: ${args.dest_dataset_id}
Next, we call the Drive API to get a list of all the CSV files in the base Drive folder provided. This call is a bit trickier because Workflows does not provide a dedicated connector for Drive, so we need to use the http.get function. This requires that we provide the full API URL path and the Authentication type we want to use, as well as the scopes needed. The query that we are sending to the API is just requesting for all of the files that have the text/csv type and have the input drive folder id as its parent. For more information on structuring the Drive API Query, you can refer to the documentation here.
- get_file_ids_from_drive: call: http.get args: url: <https://content.googleapis.com/drive/v3/files> auth: type: OAuth2 scopes: - <https://www.googleapis.com/auth/drive> query: includeItemsFromAllDrives: true supportsAllDrives: true q: ${"'" + base_drive_folder_id + "' in parents and mimeType = 'text/csv'"} result: csv_files
Now that we have a list of CSV files in the Drive folder, we can iterate through each file and load it into its own table in the destination BigQuery Dataset. We have to do a bit of string manipulation to format the source URI that the BigQuery Connector will accept:
- iterate_files: for: value: file in: ${csv_files.body.files} steps: - assign_variables_for_bq_load: assign: - source_uri: ${"<https://drive.google.com/open?id=>" + file.id} - file_name_no_ext: ${text.split(file.name, ".")[0]} - table_name: ${file_name_no_ext}
Now that we have the source URI formatted correctly, we can load the file into BigQuery. To do this, we load the CSV file into a temporary external table that we then query to create a native BigQuery table. (Note: we have to provide the needed OAuth scopes that the connector will need to get data from Drive.)
- load_file_to_bq: call: googleapis.bigquery.v2.jobs.insert args: projectId: ${dest_project_id} connector_params: scopes: - <https://www.googleapis.com/auth/drive> - <https://www.googleapis.com/auth/bigquery> body: configuration: query: createDisposition: CREATE_IF_NEEDED writeDisposition: WRITE_TRUNCATE destinationTable: projectId: ${dest_project_id} datasetId: ${dest_dataset_id} tableId: ${table_name} tableDefinitions: ${"temp_" + table_name}: sourceUris: - ${source_uri} sourceFormat: CSV csvOptions: skipLeadingRows: 1 autodetect: true query: ${"SELECT * FROM temp_" + table_name} result: load_result
And that’s it! We now have a workflow that will get all CSV type files from a Google Drive folder, read them into temporary tables, and create a BigQuery Table out of the files data.